
How to serve local web files over HTTP for testing
Recently I got interested in creating my own webapp. If you write a simple html file you can open it with a browser. Notice that in the browser in the […]
Recently I got interested in creating my own webapp. If you write a simple html file you can open it with a browser. Notice that in the browser in the […]
spark.dynamicAllocation.enabled spark.dynamicAllocation.initialExecutors spark.dynamicAllocation.minExecutors spark.dynamicAllocation.maxExecutors spark.shuffle.partitions spark.default.parallelism = spark.executor.instances * spark.executor.cores * 2 maxPartitionBytes Input bytes = 40 GB? Wähle so viele Partitions, so dass die Größe einer Partition <= 200
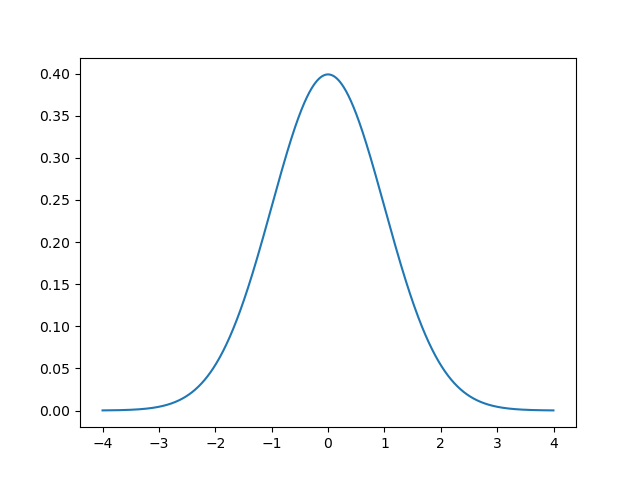
A random variable $Z$ is said to have the standard normal distribution, if its probability density function (pdf) is as follows: \[\begin{equation}f_Z(z)=\frac{1}{\sqrt{2\pi}} * \exp(\frac{-z^2}{2}), \quad -\infty<z<\infty\end{equation} \tag{1}\label{eq:eq1} \] This formula
https://gist.github.com/sallos-cyber/d2bc782f09688beefb4e66068af03174
Assumptions: zeppelin 10.0, and Spark 3.1.1. I assume Spark runs in one thread on a single machine (local) and Zeppelin runs on the same machine. The Spark-Home variable has been
Given you have created flows with nfpcapd, you can now use nfdump (more info here https://manpages.ubuntu.com/manpages/jammy/en/man1/nfdump.1.html) to write flows in a custom format to a csv-file. fmt indicates how to